Architecture
Here is how superduper works under the hood:
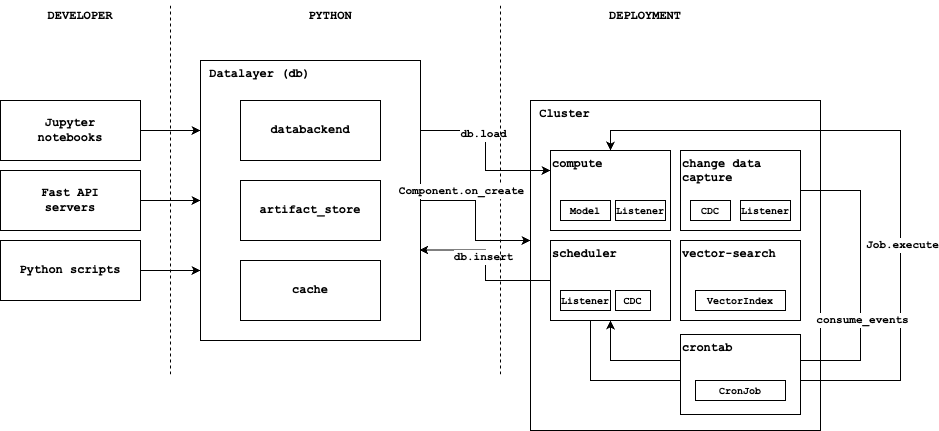
Explanation
-
Users, and developers add data and components from a range of client-side mechanisms: scripts, apps, notebooks or third-party database clients (possibly non-python).
-
Users and programs can add components (models, data encoders, vector-indexes and more) from the client-side. Large items are stored in the artifact-store and tracked in columns from the databackend.
-
Fast loading is handled with the cache
-
When components are added with
db.applythey are enqueued on the scheduler which then submits work to compute -
Certain component implementations also trigger other parts of the infrastructure (vector-search, crontab, change-data-capture)
-
If data is inserted to the databackend the change-data-capture (CDC) component captures these changes as they stream in.
-
(CDC) triggers work to be performed in response to these changes, depending on which components are present in the system.
-
The work is submitted to the workers via the scheduler. Together the scheduler and workers make up the compute layer.
-
workers write their outputs back to the databackend and trained models to the artifact-store.
-
The datalayer is the workhorse which wraps the functionality of databackend, artifact-store and cluster.
-
The datalayer is the entrypoint for activating
Componentinstances viadb.apply.